We compared the best local LLM tools for running open-weight models on your own hardware, compared on setup speed, privacy, APIs, and hardware support.
Updated June 1, 2026
Local LLM tools let you run open-weight models on your own hardware - no API keys, no per-token billing, no data leaving the machine. The category is not one thing anymore: runtimes, desktop apps, shared web UIs, and document workspaces solve different jobs. We compared more than 15 options and selected seven picks that cover the main local AI workflows.
Ollama is what most local LLM tutorials and apps assume you have running in the background. Pull a model, run it, and point any OpenAI-compatible client at the local API. It is not a polished chat app or a document workspace, but it is the shortest path from zero to a working local model that other tools can use. Treat it as the backend, not the whole product.
Platforms Type Runtime
Fastest path to a usable local API - pull a model and serve it, then point Open WebUI, AnythingLLM, a coding agent, or your own script at localhost.
Reusable model configurations - Modelfiles bake a system prompt, parameters, and base model into a named variant that behaves the same across scripts and teammates.
Clear local-vs-cloud boundary - cloud tiers exist but don’t gate local use; local hardware inference stays free and unlimited, and you can disable cloud entirely.
Not a complete workspace - it runs models but gives no polished chat UI, document workspace, or team portal; pair it with Open WebUI or AnythingLLM.
Agent tools need another layer - MCP and tool use usually depend on a client, bridge, or separate UI, so setup friction arrives fast from the runtime alone.
Best if you are wiring local models into other apps, scripts, or APIs, or running a home lab. Skip for a polished GUI - LM Studio handles that. Skip if your real workflow is documents - AnythingLLM packages that better.
LM Studio is the easiest way to see, download, chat with, and serve local models without touching a terminal. Browse the catalog in-app, watch your VRAM as inference runs, then flip on an OpenAI-compatible server when other clients need to connect. Most of the first-month friction goes away.
Platforms Type Desktop
Best desktop model browsing - search, download, compare model sizes, and watch hardware use in one app, so you know what fits your GPU before downloading weights.
Flips from GUI to local server - start in the chat window, then turn on an OpenAI- or Anthropic-compatible API for any local client, skipping the CLI runtime step.
Strong Apple Silicon path - MLX updates and MTP speculative decoding sit behind GUI toggles, the fastest way to feel a speed difference on M-series Macs.
Heavier than a minimal server - for a small always-on local model service the full desktop app feels like overhead; Ollama or llama.cpp’s server are leaner.
Advanced runtime details are abstracted - friendly defaults hide enough that you hit limits tuning unusual models or backends; llama.cpp or TextGen give more knobs.
Best if you want a friendly desktop app with a local API on tap, especially on a Mac. Skip if you need a minimal always-on server - Ollama or llama.cpp are leaner. Skip if open source is a hard requirement - try Jan.
Jan is what LM Studio would look like if you started from open-source-first principles and wanted a desktop assistant rather than a model browser. The app handles local chat, hands its models off to a CLI and OpenAI-compatible server, and is pushing toward local agent launches for coding and tool workflows. The product shape is current; some agent and router pieces are still maturing.
Platforms Type Desktop
Open-source desktop assistant - Apache 2.0, no account, familiar chat shape, useful when you want LM Studio’s feel in a tool you can inspect or fork.
Desktop models carry into the CLI - models from the GUI are available to Jan’s CLI and local server, removing duplicate setup when you wire a model into another app.
Local agent launch is built in - it pushes beyond desktop chat into local model launch for coding and agent clients pointed at local hardware.
Router controls are still settling - the CLI accepts some inference flags but ignores others, pushing tuning back through GUI presets; llama.cpp or TextGen for flag-level control.
Thinner recipe library - third-party setup and troubleshooting writeups are less plentiful than for Ollama or LM Studio, so odd failures leave you on your own more.
Best if you want LM Studio’s experience but need open source, full local control, or a CLI/API alongside the chat window. Skip if you need a team portal - Open WebUI fits that. Skip for the most battle-tested setup recipes - start with Ollama.
Open WebUI gives you the ChatGPT-style browser experience over local backends like Ollama, llama.cpp, or any OpenAI-compatible provider - without putting your prompts through a third party. You run it, usually with Docker, point it at your runtime, and end up with a multi-user web app with RBAC, SSO, and admin controls. It is a UI and platform layer, not a model runtime, so you still need something underneath it.
Platforms Type Portal
Strongest shared browser UI for local AI - it makes a single Ollama or LM Studio install feel like a team product, with multiple users, conversations, and a model picker.
Real admin controls - RBAC, groups, SSO/OIDC/LDAP, SCIM, API keys, and analytics make it the only pick here that fits an org chart and a security review.
Backend-agnostic - it sits over Ollama, OpenAI-compatible providers, and multiple model sources at once, so you swap runtimes without changing the portal.
Still need a backend underneath - it doesn’t run models itself, so pair it with Ollama, llama.cpp, LM Studio, or an OpenAI-compatible endpoint.
Ops burden grows with it - Docker, upgrades, security patches, database migrations, and auth become your problem as it scales.
Best if you need a shared browser portal over local AI with real admin controls - team, lab, classroom, or home server. Skip if you are solo and want one app to install and chat - try LM Studio. Skip for document workflows - AnythingLLM is more direct.
llama.cpp is the engine most other tools wrap, exposed for you to drive directly. C/C++ inference, GGUF support, and a long list of hardware backends (Metal, CUDA, HIP, Vulkan, SYCL, OpenVINO, WebGPU), plus llama-server for an OpenAI-compatible local API. It is not a chat app and not friendly if you are new to local models. Reach for it when a wrapper starts hiding the knob you actually need to turn.
Platforms Type Runtime
Most direct runtime control - flags, files, server behavior, context, backends, and quantization are all yours with no abstraction rounding off the decisions.
Best unusual-hardware path - AMD/Vulkan, older machines, and experimental setups are where direct build choices pay off, off the CUDA happy path.
Small scriptable server - llama-server gives a local API without a full desktop app, useful as a minimal service behind Open WebUI, a notebook, or your own app.
Requires runtime literacy - model files, flags, quantization, context, ports, backends, and sometimes build steps; if make or cmake aren’t familiar, start with Ollama.
No polished workspace - no model browser, chat app, document workspace, users, or admin, so you’ll bolt on a front end like Open WebUI for anything beyond an API.
Best if you are tuning quantization, picking backends, or running unusual hardware. Skip if you want a chat UI out of the box - try LM Studio. Skip if you want documents indexed and queried - AnythingLLM saves a lot of wiring.
AnythingLLM is the direct answer to “I want local AI over my own files.” It packages workspaces, ingestion, embeddings, citations, and provider choice around a chat window - the real product is the document workflow, not the model. It connects to a runtime (Ollama, LM Studio, an OpenAI-compatible provider, or its bundled option); you still pick the model.
Platforms Type Workspace
Best packaged document workspace - uploads, workspaces, embeddings, citations, and chat wired together, stronger than gluing a runtime, vector DB, and UI yourself.
Clear desktop vs Docker split - desktop is single-user, no account, fully local; Docker and hosted modes add multi-user, browser access, and admin, so pick upfront.
Broad ingestion and provider support - many file types, several embedding backends, multiple vector DBs, and most major LLM providers, so you swap layers without rebuilding.
Messy files still need prep - uploading .docx, spreadsheets, or scanned PDFs isn’t reliable retrieval, so expect to convert, structure folders, and tune chunking.
Best if your real workflow is documents or citations - solo or shared. Skip for a raw runtime - Ollama or llama.cpp. Skip for a generic team chat portal - Open WebUI is more direct.
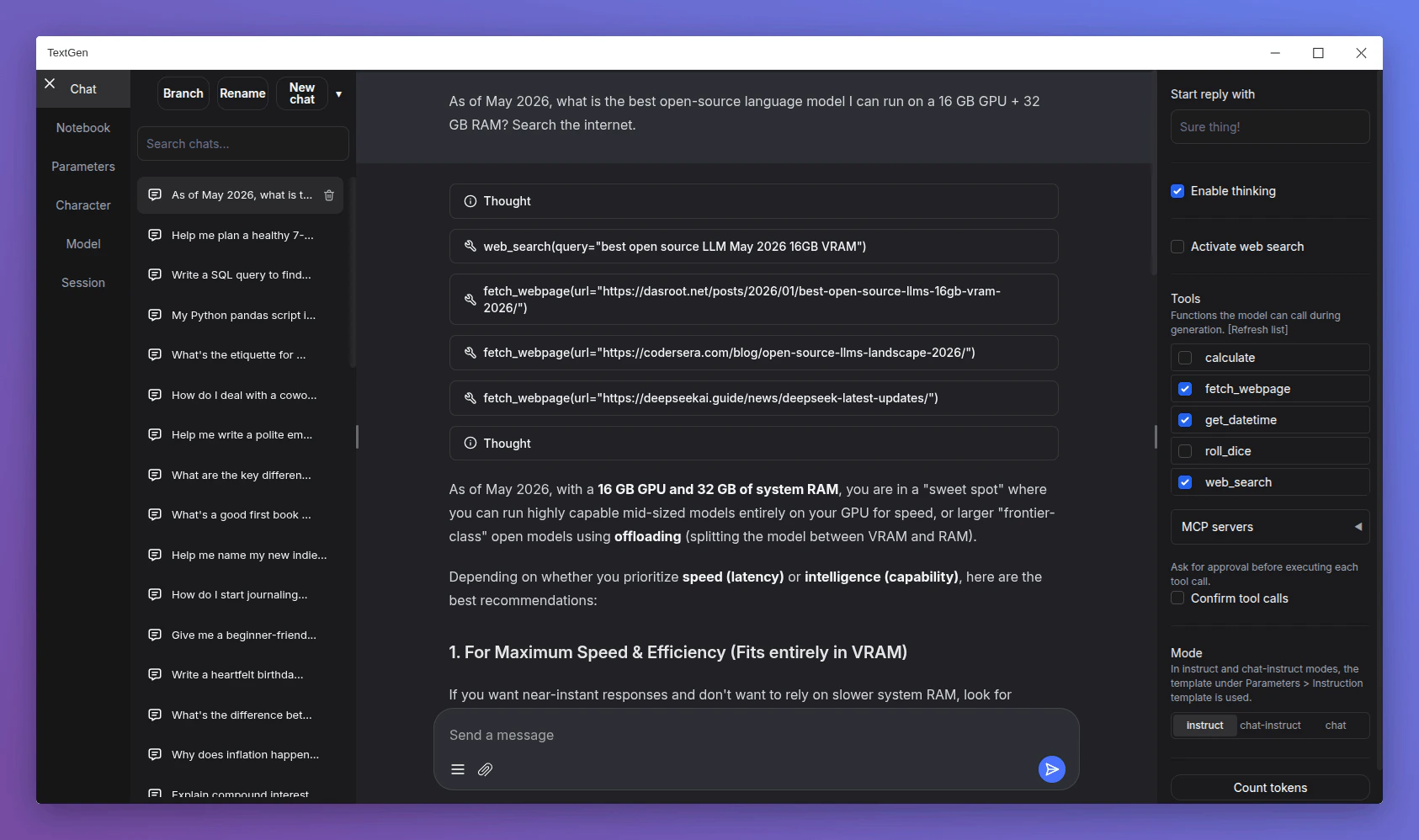
TextGen, formerly oobabooga/text-generation-webui, is the local AI workbench you reach for after outgrowing LM Studio. Portable desktop builds, OpenAI- and Anthropic-compatible APIs, MCP tool calls, multiple backends including ik_llama.cpp and ExLlama variants, web search, and PDF extraction all live in one place. It is busier and noisier than LM Studio, which is the point if you want a local lab rather than a calm app.
Platforms Type Workspace
Broad power-user workbench - chat, multiple backends, tools, files, vision, APIs, and local workflow helpers in one app for comparing backends or running a coding agent.
Portable desktop packaging - builds unzip and run as a native Electron window with all data inside the folder, useful for portability or an external drive.
Strong local API and tool story - OpenAI- and Anthropic-compatible endpoints, MCP server support, tool-call confirmation, and Python tool hooks for agent experimentation.
Too much if you just want to chat - the backends, MCP options, and tool flags that make it useful are exactly what get in the way of a simple chat; LM Studio or Jan instead.
Best if you want more control than LM Studio gives - swapping backends, running local agents with tool loops, or comparing quantizations. Skip if you are new to local models - LM Studio or Jan are calmer entry points. Skip if AGPL-3.0 is a problem for your commercial use case.
If you need a local model API for other tools, choose OllamaIf you want a polished desktop app to explore models, choose LM StudioIf you want an open-source desktop assistant, choose JanIf a team needs a shared browser portal, choose Open WebUIIf you are tuning quantization, backends, or unusual hardware, choose llama.cppIf your workflow is private documents and citations, choose AnythingLLMIf you want a power-user local lab with MCP and tools, choose TextGen
We evaluated more than 15 local LLM tools and selected seven for this guide. We do not use affiliate links, accept sponsorships, or take payment from tool makers. Pricing, platform support, licenses, and recent product changes were checked against official sources before inclusion.
We compared each tool across model setup, first useful chat, API and server behavior, hardware support, and where relevant, document ingestion and tool/agent calls. We focused on friction patterns we saw repeatedly - install pain on Windows or AMD, retrieval breaking on .docx and spreadsheets, and agent loops that work on cloud models but stall locally - rather than isolated one-off failures.
Each of these tools sits on a model you separately download. The tool license (MIT, Apache 2.0, AGPL-3.0) governs the app; the model license (Llama community, Gemma terms, Qwen license, custom non-commercial) governs the weights. Commercial use, redistribution, and hosted services need both checked. If your company has a license review process, run it once - before standardizing on a model family - rather than per-project.
Data That Leaves the Machine Even When You Don’t Mean It To
Local does not automatically mean offline. Cloud-tier features, provider API keys you wire in, web search and web fetch plugins, document ingestion that pings a remote embedder, and update checks can all send data outward. Before you assume a workflow is private, audit which features are on, set OLLAMA_NO_CLOUD=1 or its equivalent, and test with the network detached if confidentiality matters.
Anything that exposes a chat UI over the network has the security profile of a small web app - your problem, not the model’s. If you run Open WebUI or AnythingLLM Docker for other users, treat auth, HTTPS, upgrades, backups, and provider keys as part of the deployment. The model is local; the attack surface is not.
Production inference servers (vLLM, SGLang, TensorRT-LLM): Throughput, batching, and dedicated GPU serving - not personal local chat. Choose these when you are serving many people from real GPU infrastructure.
Local coding assistants and agents (Continue, Cline, Aider, OpenCode): These consume a local model endpoint rather than run the model themselves. Choose these if your real job is repo Q&A, editing files, or running terminal agents on top of a local backend.
Mobile and framework runtimes (MLX-LM, MLC LLM, WebLLM, PocketPal AI): Platform-specific stacks for Apple Silicon, phones, browsers, or embedded targets. Choose these if you are optimizing for a specific device class.
What's the difference between a local LLM runtime and a local LLM app?
A runtime like Ollama or llama.cpp loads weights and serves inference through a CLI and local API. An app like LM Studio or Jan wraps a runtime with a chat UI. Document workspaces and shared web UIs sit on top of either.
How much hardware do I really need?
Modern laptops handle 4B-8B models at 4-bit quantization. 12B-30B models comfortably need a recent GPU with 12-24GB of VRAM. 70B+ wants workstation hardware or aggressive quantization. If you are unsure, start with an 8B model in LM Studio - it shows live VRAM use.
Can I use these tools commercially?
The tool license is usually permissive (MIT, Apache 2.0). The exception is TextGen, which is AGPL-3.0 and needs review before commercial redistribution or hosted-service use. The model license is separate and varies: Llama’s community license has acceptable-use rules, Gemma has its own terms, several Qwen and DeepSeek variants are Apache 2.0. Check both before shipping.
Can a local model replace a cloud coding agent like Claude Code?
Sometimes, but rarely on the first try. Local coding agents depend on the tool harness, the model’s tool-calling reliability, the prompt format, and the hardware. A 30B-class coding model on a strong GPU handles many edits; a 7B model rarely can. Test on real tasks before switching from cloud.
Can I run multiple tools side by side?
Yes, and it is common. Ollama as the backend, Open WebUI in front, AnythingLLM pointed at Ollama for documents - a normal stack. Watch for port conflicts (11434, 1234, 7860, 8080) and shared model-file directories.
What happens to my chat history if I uninstall?
For desktop apps (LM Studio, Jan, AnythingLLM Desktop, TextGen), chats sit in the app’s local data folder - usually preserved across upgrades, removed on full uninstall. Ollama and llama.cpp do not store chats; whatever client you used does. Back up the data folder before reinstalling, and check whether the app has an export option first.
We update this guide as new tools launch and existing ones change shape. If you are still unsure, Ollama is the safest starting point - install it, then point Open WebUI or AnythingLLM at it later if you need more. Questions or suggestions? Let us know.